
Von Managern und Maschinen
Von****Erik Brynjolfsson, Andrew McAfee
Seit mehr als 250 Jahren wird das Wirtschaftswachstum von technischen Innovationen bestimmt. Die wichtigsten sind jene, die von Ökonomen als Universaltechnologien bezeichnet werden – zu dieser Kategorie gehören die Dampfmaschine, die Elektrizität oder der Verbrennungsmotor. Jede dieser Erfindungen setzte eine Welle komplementärer Innovationen und Geschäftschancen frei. Im Gefolge des Verbrennungsmotors entstanden beispielsweise Autos, Lastwagen, Flugzeuge, Kettensägen oder Rasenmäher, gleichzeitig entwickelten sich riesige Fachmärkte, Einkaufszentren, Cross-Docking-Zentren, neue Lieferketten und – etwas weiter gedacht – sogar die Wohngebiete in den Vororten. So unterschiedliche Firmen wie Walmart, UPS oder Uber fanden neue Wege, diese Technik für neue und profitable Geschäftsmodelle zu nutzen.
Die wichtigste Universaltechnologie der heutigen Zeit ist die künstliche Intelligenz (KI), und hier wiederum besonders das maschinelle Lernen (ML) – also die Fähigkeit von Maschinen, ihre Leistung zu verbessern, ohne dass Menschen ihnen genau erklären müssen, wie das zu tun ist. Besonders in den letzten paar Jahren ist das maschinelle Lernen sehr viel erfolgreicher geworden und weithin verfügbar. Wir können heute Systeme bauen, die sich sogar ihre Aufgaben selbst beibringen.
Warum das eine so große Sache ist? Aus zwei Gründen. Erstens wissen wir Menschen viel mehr, als wir ausdrücken können. Bei vielen Dingen fällt es uns sehr schwer, unsere eigene Vorgehensweise zu erklären – wie wir zum Beispiel ein Gesicht wiedererkennen oder einen klugen Zug im altasiatischen Strategiespiel Go entwickeln. In den Zeiten vor der Entwicklung des maschinellen Lernens verhinderte diese Unfähigkeit, unser Wissen zu artikulieren, die Automatisierung vieler Aufgaben. Heute aber ist das möglich.
Zweitens sind ML-Systeme häufig ausgesprochen lernfähig. Sie leisten bei vielen Aktivitäten Übermenschliches, etwa bei der Aufdeckung von Betrügereien oder der Diagnose von Krankheiten. In allen Wirtschaftsbereichen werden heute digitale Lernsysteme aufgebaut, und sie werden eine gewaltige Wirkung erzielen.
Künstliche Intelligenz wird die Wirtschaft ebenso stark verändern wie frühere Universaltechnologien. Denn obwohl sie schon in Tausenden Unternehmen weltweit eingesetzt wird, werden die meisten großen Möglichkeiten noch gar nicht genutzt. Die Auswirkungen der KI werden im kommenden Jahrzehnt um ein Mehrfaches größer sein, wenn Industrie, Einzelhandel, Logistik, Finanzen, Gesundheits- und Rechtswesen, Versicherungen, Unterhaltungsindustrie, Bildungswesen und praktisch jede andere Branche ihre Kernprozesse und Geschäftsmodelle auf die Nutzung von KI ausrichten. Die einzig beschränkenden Faktoren liegen heute im Management, bei der Einführung der Systeme und in der Vorstellungskraft der Menschen. Allerdings hat die künstliche Intelligenz wie viele neue Technologien vor ihr auch unrealistische Erwartungen geweckt. Wir sehen heute allerorten, das Businesspläne gespickt sind mit Hinweisen auf maschinelles Lernen, neuronale Netze oder andere Formen der Technologie, auch wenn das nur sehr wenig mit deren echten Einsatzmöglichkeiten zu tun hat. Wer bei der Partnervermittlung im Internet auf die Nutzung künstlicher Intelligenz verweist, verbessert dadurch nicht die Effektivität der Partnersuche, sondern allenfalls die Geldbeschaffung.
Der Zweck unseres Beitrags besteht darin, den Lärm auszufiltern und das wahre Potenzial der KI, ihre praktischen Auswirkungen und die Hindernisse bei der Umsetzung zu beschreiben.
Der Begriff Künstliche Intelligenz – englisch Artificial Intelligence – wurde 1955 von John McCarthy geprägt, einem Mathematikprofessor am Dartmouth College, der im darauffolgenden Jahr eine bahnbrechende Konferenz zu diesem Thema ausrichtete. Vielleicht lag es teilweise an der griffigen Bezeichnung, dass diesem Forschungsfeld seitdem so viele fantastische Ansprüche und Versprechungen zugeschrieben wurden. 1957 erklärte der Ökonom Herbert Simon, in zehn Jahren würden Computer Menschen beim Schach schlagen (es dauerte 40 Jahre, bis es so weit war). 1967 behauptete der Kognitionswissenschaftler Marvin Minsky: "Innerhalb einer einzigen Generation wird das Problem der Erschaffung 'künstlicher Intelligenz' weitgehend gelöst sein." Simon und Minsky waren sicher Geistesgrößen, aber hier lagen sie völlig falsch. Umso verständlicher ist es, wenn dramatische Ankündigungen bevorstehender Durchbrüche auf eine gewisse Skepsis stoßen.
Lassen Sie uns mit einer Bestandaufnahme beginnen, was KI heute schon leistet und wie schnell sie sich verbessert. Die größten Fortschritte gab es in zwei Bereichen: Wahrnehmen und Erkennen. Einige der praxistauglichsten Verbesserungen entstanden in Verbindung mit Sprache. Digitale Spracherkennung ist längst nicht perfekt, aber sie wird von Millionen Menschen genutzt – denken Sie an Siri, Alexa oder den Google Assistant.
Der Text, den Sie gerade lesen, wurde ursprünglich in einen Computer diktiert und so gut erkannt, dass es länger gedauert hätte, ihn komplett zu tippen. Eine Studie des Stanford-Informatikers James Landay und seiner Kollegen ergab, dass Spracherkennung heute im Durchschnitt dreimal so schnell ist wie das Tippen auf dem Smartphone. Die Fehlerquote ist von 8,5 Prozent auf 4,9 Prozent gesunken – und bemerkenswert daran ist, dass dies nicht in den vergangenen zehn Jahren passierte, sondern gerade mal seit Sommer 2016.
Auch die Bilderkennung hat sich erheblich verbessert. Vielleicht haben Sie bemerkt, dass Facebook und andere Apps inzwischen auf Fotos automatisch die Gesichter Ihrer Freunde erkennen und Sie auffordern, ihre Namen zuzuordnen. Eine Smartphone-App kann heute fast jeden Vogel auf einem Ast identifizieren. Bilderkennung ersetzt bereits Zugangskarten in Firmenzentralen.
Visuelle Systeme, wie sie in selbstfahrenden Autos verwendet werden, machten früher bei etwa jedem 30. Bild einen Fehler bei der Personenerkennung (so viele Bilder zeichnen die Kameras in diesen Systemen pro Sekunde ungefähr auf); heute machen sie nur alle 30 Millionen Bilder einen Fehler. Die Fehlerquote der besten Systeme bei der Bilderkennung in einer großen Datenbank mit dem Namen ImageNet, die mehrere Millionen normale, obskure und manchmal geradezu absurde Fotos enthält, sank von 30 Prozent im Jahr 2010 auf 4 Prozent 2016.
Das Tempo der Verbesserung ist in den vergangenen Jahren deutlich gestiegen, seit ein neuer Ansatz verfolgt wird, der auf sehr großen – oder vielmehr "tiefen" – neuronalen Netzen aufbaut. Dieser ML-Ansatz bei visuellen Systemen arbeitet längst nicht fehlerfrei, aber auch Menschen tun sich manchmal schwer, wenn sie in kurzer Zeit Welpengesichter erkennen sollen oder – noch peinlicher – süße kleine Tiere sehen, wo keine sind (siehe Kasten "Welpe oder Muffin").
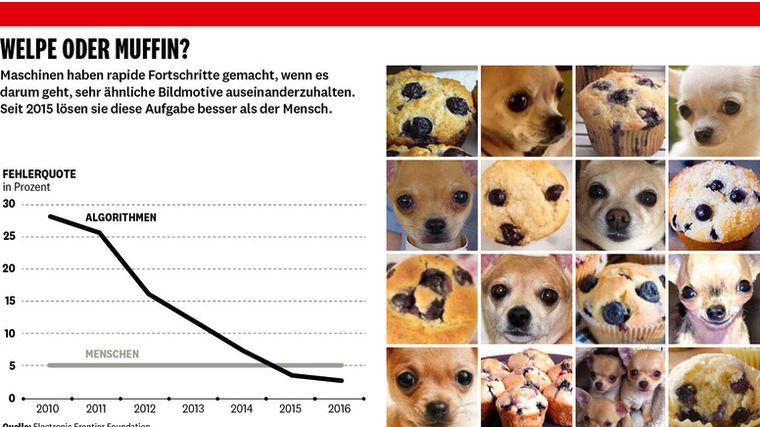
Die zweite große Verbesserung gab es bei Kognition und Problemlösung. Beim Poker und beim Go werden selbst die besten Spieler bereits von Maschinen geschlagen – eine Entwicklung, für die Experten mindestens ein weiteres Jahrzehnt veranschlagt hatten.
Das Team von DeepMind bei Google hat mithilfe lernfähiger Maschinen die Effektivität der Kühlung in ihren Datenzentren um mehr als 15 Prozent gesteigert – und das, nachdem schon menschliche Experten die Technik optimiert hatten. Das Cybersecurity-Unternehmen Deep Instinct setzt intelligente Agentensysteme für die Erkennung von Schadsoftware ein, PayPal nutzt sie zur Verhinderung von Geldwäsche. Ein anderes System auf der Basis von IBM-Technologie automatisiert die Schadensregulierung eines Versicherungsunternehmens in Singapur, und ein System der Data-Science-Plattform des Anbieters Lumidatum machte zeitnah Vorschläge für die Verbesserung des Kundendienstes. Dutzende Unternehmen setzen maschinelles Lernen für den Wertpapierhandel an der Wall Street ein, und immer mehr Kreditentscheidungen werden mithilfe von Computern getroffen. Amazon nutzt maschinelles Lernen für die Optimierung der Lagerhaltung und bessere Empfehlungen für Kunden. Infinite Analytics entwickelte ein ML-System, das half vorherzusagen, ob ein Nutzer eine bestimmte Werbung anklickt, und verbesserte damit die Platzierung von Onlineanzeigen für einen globalen Anbieter von Konsumgütern. Ein anderes System optimierte den Surf- und Suchprozess für Kunden eines brasilianischen Internethändlers. Das erste System verdreifachte die Rendite der Werbeausgaben, das zweite führte zu einer jährlichen Umsatzsteigerung von 125 Millionen US-Dollar.
ML-Systeme ersetzen nicht nur ältere Algorithmen in vielen Anwendungen, sondern erledigen heute viele Aufgaben besser als die Menschen, die sie früher durchgeführt haben. Diese Systeme sind längst nicht perfekt, aber ihre Fehlerquote – etwa 5 Prozent – in der Datenbank von ImageNet ist auf gleichem Niveau wie die von Menschen oder niedriger. Auch die maschinelle Spracherkennung ist selbst in lauten Umgebungen fast genauso gut wie die menschliche. Das Erreichen dieser Marke eröffnet riesige Möglichkeiten für die Transformation von Arbeitsplätzen und der Wirtschaft insgesamt. Wenn KI-Systeme für eine bestimmte Aufgabe besser geeignet sind als Menschen, verbreiten sie sich mit aller Wahrscheinlichkeit sehr viel schneller. Die Firmen Aptonomy und Sanbot, Anbieter von Drohnen beziehungsweise Robotern, setzen verbesserte visuelle Systeme dafür ein, viele Tätigkeiten von Sicherheitspersonal zu übernehmen. Affectiva ist einer von mehreren Softwareherstellern, die solche Systeme für das Erkennen von Emotionen wie Freude, Überraschung oder Ärger in Fokusgruppen einsetzen. Und Deep-Learning-Start-ups wie Enlitic nutzen sie dafür, bei der medizinischen Bildverarbeitung die Erkennung von Krebstumoren zu verbessern.
All das sind beeindruckende Erfolge, doch die Anwendungsmöglichkeiten von Systemen auf der Basis künstlicher Intelligenz sind heute immer noch sehr beschränkt. Zum Beispiel führt ihre beachtliche Leistung in der ImageNet-Datenbank mit ihren Millionen Bildern im echten Leben nicht immer zu ähnlichen Erfolgen, wo Licht, Winkel, Bildauflösung und Kontexte sehr unterschiedlich sein können. Auf einer allgemeineren Ebene können wir ein System bewundern, das einen chinesischen Sprecher versteht und ins Englische übersetzt, aber wir erwarten nicht, das dieses System auch die Bedeutung eines einzelnen chinesischen Schriftzeichen erkennt oder gar Tipps gibt, wo man in Peking am besten essen kann. Wenn ein Mensch in einer Tätigkeit besonders gut ist, liegt es nahe, dass er auch verwandte Aufgaben sehr gut bewältigt. Dagegen werden ML-Systeme darauf trainiert, ganz bestimmte Funktionen zu erfüllen, und ihre Kenntnisse lassen sich normalerweise nicht übertragen. Der Trugschluss, dass das spezielle Wissen eines Computers auf einem allgemeineren Verständnis beruht, ist vielleicht die Hauptursache für Missverständnisse oder Übertreibungen in Verbindung mit der Weiterentwicklung der künstlichen Intelligenz. Wir sind weit davon entfernt, Maschinen zu entwickeln, die über eine bereichsübergreifende allgemeine Intelligenz verfügen.
Wer das Prinzip von maschinellem Lernen verstehen will, muss sich vor allem eines klarmachen: Diese Technik verfolgt einen grundlegend anderen Ansatz als die Softwareentwicklung. Der Computer lernt anhand von Beispielen, er wird also nicht auf ein bestimmtes Ergebnis hin programmiert. Das ist ein wichtiger Unterschied zu der bisher üblichen Praxis. In den vergangenen 50 Jahren war es in der Regel so, dass Fortschritte in der Informationstechnik und deren Anwendungen auf der Kodifizierung bestehenden Wissens oder bestehender Prozesse beruhten, die auf Computer übertragen wurden. Der deutsche Begriff "Programmieren" oder das englische "Coding" beschreiben den mühsamen Prozess, das Wissen in den Köpfen der Softwareentwickler in eine Form zu bringen, die Maschinen verstehen und ausführen können. Diese Herangehensweise hat einen entscheidenden Nachteil: Der Großteil unseres Wissens ist nur implizit vorhanden. Wir können keine genaue Anleitung aufschreiben, mit deren Hilfe ein anderer Mensch das Fahrradfahren lernt oder das Gesicht eines Freundes erkennt.
Anders formuliert: Wir alle wissen mehr, als wir ausdrücken können. Diese Tatsache ist so wichtig, dass sie eine eigene Bezeichnung hat: Das Polanyi-Paradoxon, benannt nach dem Philosophen und Universalgelehrten Michael Polanyi, der es 1964 beschrieb. Das Polanyi-Paradoxon behindert uns nicht nur bei der Weitergabe von Wissen, sondern schränkt fundamental unsere Fähigkeit ein, Maschinen mit Intelligenz auszustatten. Das verringerte über eine lange Zeitspanne hinweg die Zahl der Aufgaben, die Computer in der Wirtschaft produktiv erledigen konnten.
Das maschinelle Lernen überwindet diese Beschränkungen. In der sich jetzt ausbreitenden zweiten Welle des zweiten Maschinenzeitalters lernen von Menschen gebaute Maschinen von Beispielen und nutzen strukturiertes Feedback, um Probleme selbst zu lösen – unter anderem auch die schon von Polanyi beschriebene Aufgabe der Gesichtserkennung.
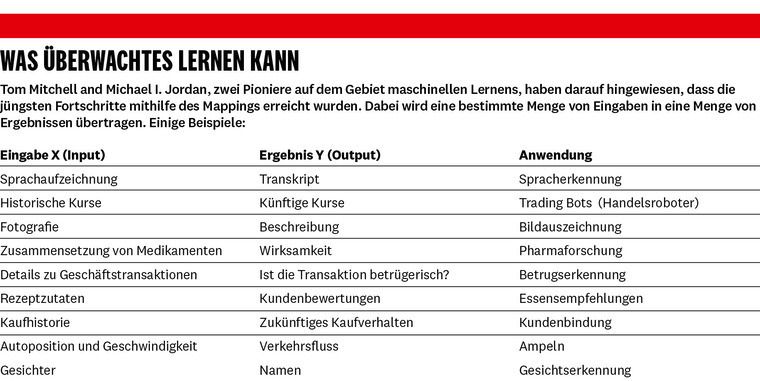
Künstliche Intelligenz und maschinelles Lernen gibt es in vielerlei Formen, doch die größten Fortschritte der vergangenen Jahre gab es in einer Kategorie: beim überwachten Lernen. Dabei werden dem Computer viele Beispiele für richtige Antworten für eine bestimmte Aufgabe gegeben. Dabei findet fast immer die Übertragung ("Mapping") einer Menge von Eingaben (X) in eine Menge von Ergebnissen (Y) statt. Die Eingaben – oder Inputs – können zum Beispiel Bilder verschiedener Tiere sein, und die korrekten Ergebnisse – oder Outputs – sind dann Bezeichnungen für diese Tiere: Hund, Katze, Pferd. Als Input können auch die Daten einer Tonaufnahme und als Output Wörter wie "Ja", "Nein", "Guten Tag" oder "Auf Wiedersehen" dienen (siehe Tabelle "Was überwachtes Lernen kann").
Erfolgreich arbeitende Systeme verwenden oft ein Trainingsset mit den Daten von Tausenden oder sogar Millionen Beispielen, denen jeweils eine korrekte Antwort zugeordnet ist. Das System wird dann auf neue Beispiele losgelassen. Wenn das Training gut war, kann es in diesen Fällen die richtigen Antworten mit einer hohen Genauigkeit vorhersagen.
Die Algorithmen, mit denen diese Erfolge erreicht wurden, basieren auf einem Ansatz, der als tiefes Lernen (Deep Learning) bezeichnet wird und neuronale Netze verwendet. Solche Algorithmen haben gegenüber ihren Vorgängern beim maschinellen Lernen einen signifikanten Vorteil: Sie können erheblich größere Datensätze verarbeiten. Auch die alten Systeme verbesserten sich mit jedem neuen Beispiel in den Trainingsdaten – aber nur bis zu einem gewissen Punkt, ab dem zusätzliche Daten keine Verbesserung mehr brachten. Nach Ansicht von Andrew Ng, einer der führenden Kapazitäten auf diesem Gebiet, scheint es diese Beschränkung bei neuronalen Netzen nicht zu geben: Mehr Daten führen zu immer besseren Vorhersagen. Einige sehr große Systeme werden im Training bereits mit 36 Millionen Beispielen und mehr gefüttert. Natürlich erfordert dieser Umgang mit sehr großen Datenmengen immer mehr Rechenleistung, deshalb laufen diese riesigen Systeme oft auf Supercomputern oder nutzen spezielle Computerarchitekturen.
Systeme überwachten Lernens sind immer dann eine Option, wenn Sie sehr viele Daten über ein Verhalten haben und daraus Vorhersagen ableiten wollen. Nach Aussage von Jeff Wilke, bei Amazon für das Privatkundengeschäft zuständig, haben solche Systeme bei der Erstellung personalisierter Empfehlungen für Kunden bereits weitgehend die bisherigen Filteralgorithmen auf der Basis von Datenbanken abgelöst. In anderen Fällen wurden die klassischen Algorithmen für die Bestimmung des Inventars oder für die Optimierung der Lieferketten durch effizientere und robustere Systeme auf der Basis maschinellen Lernens ersetzt. J. P. Morgan Chase führte ein System für die Prüfung kommerzieller Kreditverträge ein: Die Arbeit, mit der Kreditsachbearbeiter früher 360.000 Stunden beschäftigt waren, kann heute innerhalb weniger Sekunden erledigt werden. Und computergesteuertes überwachtes Lernen wird heutzutage bei der Diagnose von Hautkrebs eingesetzt. Dies sind nur einige Beispiele von vielen.
Es ist relativ unkompliziert, einen Datensatz konkret zu benennen und ihn dann für das Training im überwachten Lernen zu verwenden, deshalb sind überwachte ML-Systeme verbreiteter als unüberwachte, zumindest heute noch. Unüberwachte Systeme lernen selbstbestimmt. Wir Menschen zum Beispiel können ausgezeichnet unüberwacht lernen: Wir bilden uns unser Wissen über die Welt (etwa das Wissen, wie wir einen Baum erkennen) anhand sehr weniger oder gar keiner konkret benannten Daten. Aber es ist ausgesprochen schwer, ein maschinelles Lernsystem zu entwickeln, das so arbeitet.
Falls und wenn wir robuste Systeme auf der Basis unüberwachten Lernens entwickeln können, werden sich für uns aufregende Möglichkeiten eröffnen. Solche Computer könnten auf ganz neue Weise komplexe Probleme betrachten und uns helfen, Muster zu erkennen – bei der Verbreitung von Krankheiten, bei Preisschwankungen von Wertpapieren oder dem Kaufverhalten von Kun-den –, von denen wir heute nichts wissen. Diese Erkenntnis steckt dahinter, wenn Yann LeCun, Chef der KI-Forschung bei Facebook und Profes- sor an der New York University, das überwachte Lernen mit dem Zuckerguss eines Kuchens und das unüberwachte Lernen mit dem Kuchen selbst vergleicht.
Ein weiterer kleiner, aber wachsender Bereich ist das bestärkende Lernen. Ein solcher Ansatz wird von Systemen verwendet, die Atari-Videospiele oder Brettspiele wie Go meistern. Es ist aber auch hilfreich bei der Energiesteuerung von Datenzentren oder der Entwicklung von Handelsstrategien für die Börse. Roboter der Firma Kindred nutzen maschinelles Lernen dafür, ihnen bisher unbekannte Objekte zu identifizieren und zu sortieren. Das beschleunigt die Positionierprozesse in Vertriebszentren für Konsumgüter. Beim bestärkenden Lernen beschreibt der Programmierer den bestehenden Status des Systems und dessen Ziel, listet erlaubte Aktionen auf und beschreibt die Elemente im Umfeld, durch die das Ergebnis dieser Aktionen eingeschränkt wird. Das System muss dann herausfinden, wie es mittels der erlaubten Aktionen das Ziel so gut wie möglich erreicht. Eine solche Methode funktioniert immer dann gut, wenn Menschen das Ziel festlegen, aber nicht unbedingt den Weg dorthin. Microsoft nutzte bestätigendes Lernen zum Beispiel bei der Auswahl von Überschriften auf der Nachrichtenseite msn.com, indem es Computer für Überschriften, die viele Klicks erhielten, mit Punkten "belohnte". Das System versuchte dann, unter Einsatz der Mittel, die ihm die Entwickler gestatteten, seinen Punktestand zu maximieren. Daraus folgt natürlich, dass ein System bestätigenden Lernens sich auf das Ziel ausrichtet, das explizit vorgegeben wird – und das nicht unbedingt mit dem eigentlich angestrebten Ziel (zum Beispiel dem Customer Lifetime Value) identisch ist. Es kommt also entscheidend darauf an, das Ziel richtig und klar festzulegen.
Es gibt drei gute Nachrichten für Organisationen, die maschinelles Lernen heute nutzen wollen. Erstens verbreitet sich künstliche Intelligenz sehr schnell. Zwar gibt es noch nicht annähernd genug Datenforscher und ML-Experten, aber der steigende Bedarf wird von Onlinebildungsangeboten ebenso wie von Universitäten gedeckt. Die besten, darunter Udacity, Coursera und fast.ai, leisten mehr als nur die Vermittlung einführender Konzepte, sie befähigen kluge und motivierte Studenten durchaus dazu, industrietaugliche ML-Systeme zu entwickeln. So können interessierte Unternehmen nicht nur die eigenen Leute weiterbilden, sondern auf Onlinejobplattformen wie Upwork, Topcoder oder Kaggle ML-Experten mit überprüfbaren Kenntnissen finden.
Die zweite positive Entwicklung besteht darin, dass die notwendigen Algorithmen oder die Hardware für moderne künstliche Intelligenz ganz nach Bedarf gekauft oder gemietet werden können. Google, Amazon, Microsoft, Salesforce und andere Unternehmen stellen über die Cloud eine leistungsfähige ML-Infrastruktur bereit. Der brutale Wettbewerb zwischen diesen Rivalen führt dazu, dass Unternehmen mit der Zeit immer bessere und billigere Angebote finden, wenn sie mit maschinellem Lernen experimentieren wollen.
Die dritte und wahrscheinlich am stärksten unterschätzte positive Tatsache ist die, dass vielleicht gar nicht so viele Daten nötig sind, um maschinelles Lernen produktiv zu nutzen. Die meisten Systeme verbessern sich, wenn sie mit größeren Datenmengen arbeiten. Es scheint also ein logischer Schluss zu sein, dass das Unternehmen gewinnt, das über die meisten Daten verfügt. Vielleicht ist das sogar der Fall, wenn "gewinnen" bedeutet, "den Weltmarkt für eine einzelne Anwendung wie die Zielgruppenwerbung oder Spracherkennung zu dominieren". Aber wenn sich Erfolg schon darin ausdrückt, die Leistung zu verbessern, lassen sich ausreichende Daten oft erstaunlich leicht finden.
Sebastian Thrun, der Mitbegründer von Udacity, beobachte zum Beispiel, dass einige seiner Vertriebsmitarbeiter Anfragen in einem Chatroom sehr viel effektiver bearbeiteten als andere. Thrun und sein Doktorand Zayd Enam erkannten, dass ihre Chatroom-Logbücher im Prinzip einen Satz gekennzeichneter Trainingsdaten darstellten – also genau das, was ein System des überwachten Lernens braucht. Interaktionen, die zu einem Abschluss führten, waren als Erfolg gekennzeichnet, die anderen als Misserfolg. Zayd verwendete die Daten für die Erstellung einer Prognose, welche Antworten ein erfolgreicher Vertriebsmitarbeiter auf typische Fragen gibt, und leitete diese Informationen an alle Vertriebsleute weiter. Nach 1000 Trainingsdurchgängen hatten die Verkäufer ihre Erfolgsquote um 54 Prozent gesteigert und konnten in derselben Zeit doppelt so viele Kunden beraten.
Das KI-Start-up WorkFusion verwendet einen ähnlichen Ansatz. Es arbeitet gemeinsam mit anderen Unternehmen daran, Backoffice-Tätigkeiten wie das Bezahlen internationaler Rechnungen oder die Abwicklung des Handels zwischen Finanzinstituten stärker als bisher zu automatisieren. Bislang geschah das nicht, weil diese Aufgaben kompliziert sind, relevante Informationen nicht zu jeder Zeit in derselben Form zur Verfügung stehen ("Woher wissen wir, welche Währung gemeint ist?") und deshalb Interpretationen und Urteile nötig sind. Die Software von WorkFusion beobachtet im Hintergrund die Mitarbeiter bei der Arbeit und verwendet deren Aktionen als Trainingsdaten für die kognitiven Aufgaben der Klassifizierung ("Diese Rechnung ist in US-Dollar ausgestellt, diese in Yen und diese in Euro ..."). Sobald sich das System der eigenen Klassifizierungen sicher ist, übernimmt es den Prozess selbst.
Maschinelles Lernen sorgt auf drei Ebenen für Veränderungen: bei Aufgaben und Tätigkeiten, bei den Geschäftsprozessen und bei den Geschäftsmodellen. Ein Beispiel für Veränderungen auf der Ebene der Aufgaben und Tätigkeiten ist die Verwendung computergesteuerter optischer Systeme bei der Identifizierung möglicher Krebszellen – so können sich Radiologen auf die wirklich schwierigen Fälle konzentrieren, ausführlicher mit Patienten sprechen oder sich intensiver mit anderen Ärzten austauschen. Ein Beispiel für Prozessverbesserungen ist die Anpassung des Arbeitsflusses und der räumlichen Gestaltung von Umschlaglagern bei Amazon aufgrund des Einsatzes von Robotern und Optimierungsalgorithmen auf der Basis maschinellen Lernens. Auf ähnliche Weise müssen ganze Geschäftsmodelle neu durchdacht werden, damit ML-Systeme etwa für die intelligente personalisierte Empfehlung von Musik oder Filmen eingebunden werden können. Statt Songs à la carte auf der Basis bisheriger Kundenentscheidungen anzubieten, könnte ein besseres Modell das Abonnement eines persönlichen Kanals empfehlen, auf dem Musik vorgeschlagen und gespielt wird, die dem Kunden gefallen würde, auch wenn er sie noch nie zuvor gehört hat.
Beachten Sie, dass ML-Systeme fast niemals ganze Jobs, Prozesse oder Geschäftsmodelle ersetzen. Meistens ergänzen sie menschliche Tätigkeiten und machen sie dadurch wertvoller. Die beste Regel für die neue Arbeitsteilung lautet nur selten "Übertrage der Maschine alle Aufgaben". Wenn die erfolgreiche Bewältigung eines Prozesses aus zehn Schritten besteht, werden vielleicht zwei automatisiert, während die anderen immer noch besser von Menschen erledigt werden. Das Unterstützungssystem für die Verkäufer von Udacity versuchte beispielsweise erst gar nicht, eine automatisierte Lösung für die Verkaufsgespräche zu finden, sondern diente nur dazu, die Arbeit der Vertriebler zu verbessern. Die Menschen blieben für ihrer Aufgaben verantwortlich, aber sie wurden sehr viel effektiver und effizienter. Ein solcher Ansatz ist in der Regel sehr viel geeigneter als der Versuch, Maschinen zu entwickeln, die alle menschlichen Tätigkeiten übernehmen können. Die Arbeit der betroffenen Menschen verbessert sich auf diese Weise, macht sie zufriedener und führt langfristig zu besseren Ergebnissen für die Kunden.
Die Entwicklung und Einführung neuer Kombinationen aus Technologie, menschlichen Fähigkeiten und Kapital, um Kundenbedürfnisse zu erfüllen, erfordert Kreativität und Planung in großem Maßstab. Dafür sind Maschinen nicht besonders gut geeignet. Deshalb ist die Rolle des Entrepreneurs oder Managers im Zeitalter des maschinellen Lernens eine der besten Aufgaben, die die Gesellschaft zu bieten hat.
Die zweite Welle des zweiten Maschinenzeitalters bringt neue Risiken mit sich. Eines besteht darin, dass Menschen nur sehr schlecht nachvollziehen können, wie ML-Systeme zu ihren Entscheidungen gekommen sind. Umfangreiche neuronale Netze umfassen vielleicht Hunderte Millionen Verbindungen, die jeweils einen eigenen kleinen Beitrag zu der Gesamtentscheidung beisteuern. Entsprechend lassen sich diese Systeme kaum auf einfache Art und Weise erklären. Anders als Menschen sind Maschinen (noch) keine guten Geschichtenerzähler, sie können nicht immer rational erklären, warum ein Bewerber dem anderen vorgezogen oder warum ein bestimmtes Medikament empfohlen wurde. Die Ironie dabei: Gerade haben wir uns darangemacht, das Polanyi-Paradoxon zu überwinden, schon müssen wir uns mit einer Art gegenteiliger Version davon auseinandersetzen. Maschinen wissen mehr, als sie uns sagen können.
Das birgt drei Risiken: Erstens können die Maschinen versteckte Vorurteile aufbauen – nicht, weil sie ihnen von Softwaredesignern einprogrammiert wurden, sondern aufgrund der ihnen im Training zur Verfügung gestellten Daten. Wenn ein System zum Beispiel auf der Basis von Daten über frühere menschliche Entscheidungen lernt, welche Bewerber angenommen werden sollen, übernimmt es unbeabsichtigt auch die Vorurteile der Menschen gegenüber Rasse, Geschlecht, Nationalität et cetera. Erschwerend kommt hinzu, dass all diese Einseitigkeiten nicht als explizite Regel auftauchen, sondern vielmehr in den vielen subtilen Abwägungen unter Tausenden herangezogenen Faktoren versteckt sind.
Ein zweites Risiko besteht darin, dass Systeme neuronaler Netze anders als traditionelle Systeme nicht auf expliziten logischen Regeln aufbauen. Sie setzen eher auf statistische als auf buchstäbliche Wahrheiten. Das macht es schwierig bis unmöglich, zweifelsfrei nachzuweisen, dass das System in jeder Situation funktioniert – also auch in Fällen, die in den Trainingsdaten nicht vorkamen. Diese fehlende Nachweisbarkeit kann zum Problem werden, wenn es um erfolgskritische Aufgaben wie die Steuerung eines Atomkraftwerks oder um Entscheidungen über Leben oder Tod geht.
Drittens wird es fast unmöglich sein, bei den unvermeidlich auftretenden Fehlern eines ML-Systems festzustellen, wie es dazu gekommen ist und wie sie zu beheben sind. ML-Systeme entscheiden auf der Basis unvorstellbar komplexer Strukturen, und ihre Lösungen sind vielleicht alles andere als optimal, wenn sich die Bedingungen ändern, unter denen sie trainiert wurden.
Aber auch angesichts dieser realen Risiken geht es nicht um Perfektion, sondern um die beste Alternative. Schließlich haben auch wir Menschen Vorurteile, machen Fehler und können nicht jede Entscheidung genau erklären. Maschinenbasierte Systeme haben den Vorteil, dass sie mit der Zeit verbessert werden können und konsistente Antworten auf einer vorgegebenen Datenbasis liefern.
Bedeutet all dies, dass es für künstliche Intelligenz oder maschinelles Lernen keine Grenzen gibt? Wahrnehmen und Erkennen decken schon große Bereiche ab – das Steuern von Autos, die Prognose von Verkaufszahlen oder die Stellenbesetzung und Beförderung. Wir glauben, dass KI mit großer Wahrscheinlichkeit schon bald auf allen oder einigen dieser Gebiete übermenschliche Fähigkeiten entwickelt. Aber was werden künstliche Intelligenz und maschinelles Lernen nicht können?
Oft hören wir den Einwand: "Künstliche Intelligenz wird nie in der Lage sein, emotionale, listige, schlaue und unbeständige Menschen wirklich einzuschätzen – dafür ist sie einfach zu starr und zu unpersönlich." Wir glauben nicht, dass das stimmt. ML-Systeme wie die von Affectiva, einer Ausgründung des Bostoner MIT Media Lab, können auf der Basis von Gesichtsausdruck oder Stimmlage beurteilen, in welcher Stimmung jemand ist – und das können sie schon besser als Menschen. Andere Systeme erkennen selbst bei den besten menschlichen Pokerspielern Bluffs ausreichend gut, um sie bei den komplexesten Spielvarianten zu schlagen. Menschen zuverlässig einzuschätzen ist subtil, aber keine Zauberei; die Fähigkeiten Wahrnehmen und Erkennen sind dazu nötig, also genau das, was maschinelles Lernen auszeichnet und in der Zukunft immer besser beherrschen wird. Ein schöner Gesprächseinstieg über die Grenzen der künstlichen Intelligenz ist die Bemerkung, die Pablo Picasso über Computer machte: "Sie sind nutzlos! Sie können nur Antworten geben." Die jüngsten Erfolge maschinellen Lernens zeigen, dass Computer alles andere als nutzlos sind, aber die Äußerung Picassos gibt dennoch einen wichtigen Einblick. Computer sind Maschinen, um Fragen zu beantworten, nicht um sie zu stellen. Auch in Zukunft muss es Entrepreneure, Erfinder, Wissenschaftler, Kreative und andere Menschen geben, die herausfinden, welches Problem oder welche Möglichkeit als Nächstes in Angriff genommen oder welches neue Gebiet erkundet werden sollte.
Ein vergleichbarer Unterschied besteht darin, die Stimmung eines Menschen nur zu erfassen oder diese aktiv zu verändern. ML-Systeme beherrschen die erste Aufgabe ziemlich gut, doch bei der zweiten lassen sie sich von uns leicht schlagen. Wir Menschen sind eine zutiefst soziale Spezies; nicht Maschinen, sondern Menschen können am besten soziale Kräfte wie Mitleid, Stolz, Solidarität oder Scham dafür nutzen, andere zu überzeugen, zu motivieren und zu inspirieren. 2014 schrieben die TED-Konferenz und die Xprize Stiftung eine Prämie aus für die "erste künstliche Intelligenz, die einen TED-Talk so überzeugend präsentiert, dass sie stehende Ovationen von den Zuhörern bekommt". Wir bezweifeln, dass die Prämie in nächster Zeit ausgezahlt wird.
Wir glauben, dass im Zeitalter superstarken maschinellen Lernens die größten und wichtigsten Möglichkeiten für menschliche Intelligenz in der Schnittmenge zweier Aufgaben entstehen: zu entscheiden, was als Nächstes zu tun ist, und ausreichend viele Menschen davon zu überzeugen, diese Aufgaben zu lösen und mit den Ergebnissen weiterzumachen. Das ist eine ganz gute Definition von Führungsstärke – und genau die wird im zweiten Maschinenzeitalter sehr viel wichtiger.
Die Form, wie Arbeit derzeit zwischen Menschen und Maschinen verteilt ist, wird sich schon bald auflösen. Unternehmen, die daran festhalten, werden immer größere Wettbewerbsnachteile gegenüber jenen Rivalen erleiden, die bereit und in der Lage sind, maschinelles Lernen in allen geeigneten Bereichen einzusetzen und herauszufinden, wie sich diese Fähigkeiten mit denen der Menschen effektiv verknüpfen lassen. In der Wirtschaft hat eine Zeit tektonischer Verschiebungen begonnen, ausgelöst durch technischen Fortschritt. Wie in der Zeit von Dampfmaschine und Elektrizität unterscheiden sich die Gewinner von den Verlierern weder durch den Zugang zu der neuen Technik selbst noch durch die besten Techniker. Gewinner sind stattdessen die Innovatoren, die mit offenem Blick über den Status quo hinausblicken, die sich neue Herangehensweisen vorstellen können und geschickt genug sind, diese umzusetzen. Eines der größten Vermächtnisse des maschinellen Lernens kann durchaus darin bestehen, eine neue Generation von Führungskräften erschaffen zu haben.
Unserer Ansicht nach ist künstliche Intelligenz, und vor allem das maschinelle Lernen, die wichtigste Universaltechnologie unserer Zeit. Ihre Wirkung auf Unternehmen und Wirtschaft wird sich nicht nur in ihren direkten Beiträgen zeigen, sondern auch darin, wie sie komplementäre Erfindungen ermöglicht und inspiriert. Neue Produkte und Prozesse entstehen durch bessere optische Geräte, Spracherkennung, intelligentes Problemlösen und viele andere Fähigkeiten, in denen maschinelles Lernen glänzt.
Einige Experten gehen noch weiter. Gill Pratt, Leiter des Toyota Research Centers, hat die derzeitige Welle der künstlichen Intelligenz mit der Kambrischen Explosion verglichen, die vor 500 Millionen Jahren eine gewaltige Vielfalt neuer Lebensformen hervorbrachte. Damals wie heute war das Sehen eine neue Fähigkeit. Den Tieren erlaubte es ein sehr viel effizienteres Erkunden ihrer Umgebung; als Folge entstanden neue Spezies – Jäger wie Beute – und eine Vielzahl ökologischer Nischen, die gefüllt werden konnten. Auch heute sehen wir neue Produkte, Dienstleistungen, Prozesse und Unternehmensformen – und vieles, das ausstirbt. Es wird in Zukunft sicher seltsame Misserfolge und überraschende Erfolge geben.
Auch wenn sich nur schwer vorhersagen lässt, welche Unternehmen die neue Welt in Zukunft dominieren werden, ein grundlegendes Prinzip lässt sich schon heute klar erkennen: Die geschicktesten und anpassungsfähigsten Unternehmen und Führungskräfte werden erfolgreich sein. Organisationen, die Chancen schnell erkennen und verfolgen, werden die Vorteile der KI-Landschaft nutzen können. Die beste Strategie ist also, mit hohem Tempo zu experimentieren und zu lernen. Manager, die nicht verstärkt mit lernenden Maschinen experimentieren, erfüllen ihre Aufgabe nicht. Im nächsten Jahrzehnt wird künstliche Intelligenz die Manager nicht ersetzen. Aber Manager, die diese Technologie nutzen, werden jene verdrängen, die das nicht tun. 
Von Erik Brynjolfsson, Andrew McAfee
Die Autoren
Erik Brynjolfsson leitet den Bereich Digitale Wirtschaft am Massachusetts Institute of Technology (MIT) und ist Professor für Management an der Sloan School of Management des MIT. Außerdem arbeitet er als Wissenschaftler für die Nonprofit-Organisation National Bureau of Economic Research. Er untersucht die Auswirkungen der Informationstechnik auf Geschäftsstrategien, Produktivität und Leistung, digitalen Handel und immaterielle Wirtschaftsgüter.
Andrew McAfee arbeitet als Principal Research Scientist am MIT und untersucht, wie digitale Technologien Unternehmen, Wirtschaft und Gesellschaft verändern. Gemeinsam mit Erik Brynjolfsson schrieb er "Machine, Platform, Crowd: Harnessing Our Digital Future" (2017) und "The Second Machine Age: Work, Progress, and Prosperity in a Time of Brilliant Technologies" (2014).
© HBP 2019